extremely online #1: a tech accountability round-up

This is Extremely Online, a tech accountability round-up by Julie Lee.
TL;DR: This newsletter is for people who care about tech and AI accountability, with original work, upcoming events and job and funding opportunities. Subscribe.
Who am I? I'm an investigative data journalist that writes about tech and AI. I have been a Technology Fellow at the ACLU of Massachusetts, research intern at the Surveillance Technology Oversight Project and Public Voices Fellow on Technology in the Public Interest. I’ve written stories on how civil asset forfeiture funded robot police dogs, the largest analysis to date of ShotSpotter’s efficacy in Boston, Kickstarter United’s historic fight for a four day work week, and that sad time Evernote killed its free tier. I've worked on projects about Flock, automated license plate readers and location data brokers that haven't made it onto the internet but that I'm hoping can inform future editions. Oh yeah, and I have a Ph.D. in neuroscience, for some reason.
Most importantly for you, I’m someone who loves sending people resources, like news and events and jobs relevant to them. I realized I could make that useful to a wider audience.
Saving Lina Khan from the memory hole
In this newsletter, I plan to share quick dispatches of original reporting or revisit old projects. I have some story ideas in the works and I’m looking forward to sharing them. But to start, I wanted to return to a project I worked on almost exactly a year ago, when I was the Technology for Liberty Fellow at the ACLU of Massachusetts.
The Technology for Liberty team worked on issues at the intersection of technology and civil rights and civil liberties. We relied on a lot of important data and documents from federal agencies. When Trump won, we realized that he might erase records of the previous administration's work on tech and AI policy. So, we decided to save what we could. Or, as my old boss Kade Crockford put it:

To do this, I explored different ways of crawling through a website and saving all links, but that was going to return a lot of bloat we weren’t interested in. The most useful strategy for our purposes turned out to be defining a list of documents we were most interested in, and programmatically downloading those links, while using the Wayback Machine API to backup the same page for an extra safeguard. Finally, we published a searchable table of the 250+ documents we identified as relevant to tech policy and AI.
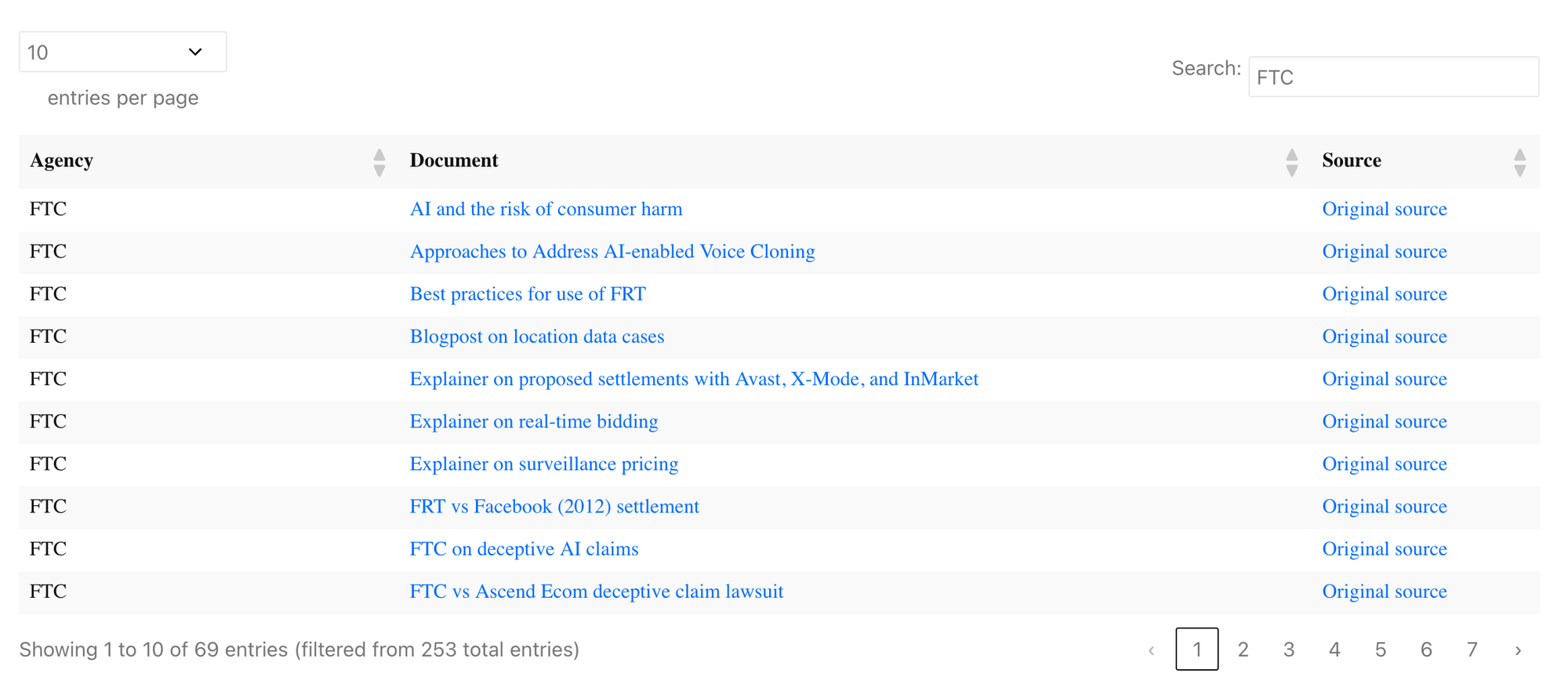
This idea turned out to be prescient almost immediately, when the new administration started taking down links. In March 2025, WIRED reported that FTC was taking down content critical of Big Tech companies, and in October 2025, they reported that blog posts on risks of AI were being taken down. Fear not.
The project ended up being illustrative of two principles I hold: (1) don't reinvent the wheel and (2) the solution is usually not the most technical (corollary: meet people where they are). While scoping the project, I learned about the Internet Archive's End of Term archive and the ArchiveBot, which manages a chatroom where people can request whole sites to be archived. (Here's a fun dashboard of all the sites currently being crawled by the bot.) I wasn't going to replicate what others were already doing well, but there were gaps that I could try to fill. While I could have used a fancy programmatic method to achieve this, that also would have taken more time to implement than it was worth and probably ended up being less useful to our exact use case. In the end, a tailored list of our top picks, in a simple searchable table, felt like the right fit.
Okay, that's enough from me. Read on for upcoming events and job/funding opportunities in tech and AI accountability.
Upcoming events
Monday, February 9 (NYC, virtual): When Clinical Judgement and AI Diverge, Columbia University School of Professional Studies
Monday, February 9 (virtual): Discovering NYC Open Data, NYC Open Data Ambassadors
Tuesday, February 10 (NYC): AI in Business Initiative Fireside Chat with Dr. Ronnie Chatterji, Chief Economist, OpenAI, Columbia Business School
Tuesday, February 10 (Cambridge, virtual): Data Privacy and the Future of AI Governance: A Conversation with Former FTC Commissioner Julie Brill, Berkman Klein Center
Thursday, February 12 (NYC): Teach-in on AI, the internet of shit and the great capitalist sloppification, Kudzu Club
Monday, February 16 (NYC, virtual): The Moral Economy of Using Real-Time Driving Data to Price Car Insurance, Columbia University Center for Science and Society
Thursday, February 19 (virtual): Effective Redress for AI Harms in Europe: Charting a Path Forward, Center for Democracy and Technology
Wednesday, March 4 (NYC): Mapping AI: Labor, Columbia University Center for Science and Society
April 15-16 (Perugia, Italy): Knowledge-sharing Event on “International reporting practices and AI guidelines," Media Organisations for Stronger Transnational Journalism
April 17-19 (Atlanta, Georgia): Take Back Tech, Mijente and Media Justice
Self-paced (virtual): AI Spotlight Series, Pulitzer Center
Jobs and funding opportunities
Postdoctoral researcher, Public Tech Media Lab, UW Madison
Research Director, Center for Democracy & Technology
Director, AI Opportunity, MacArthur Foundation
Operations Manager, Knight-Georgetown Institute
Call for Collaborators to Develop Learning Resources and Training for Investigators, Tactical Tech
Liked what you read?
Thanks so much for joining this first experiment! Please sign up if you want more of this, and I would love any feedback, so please feel free to reach out or fill the feedback form at the bottom if you have any thoughts.
I'd love your feedback if you have a second: